Risultati preliminari del pilot di 30 giorni — e cosa raccontano davvero
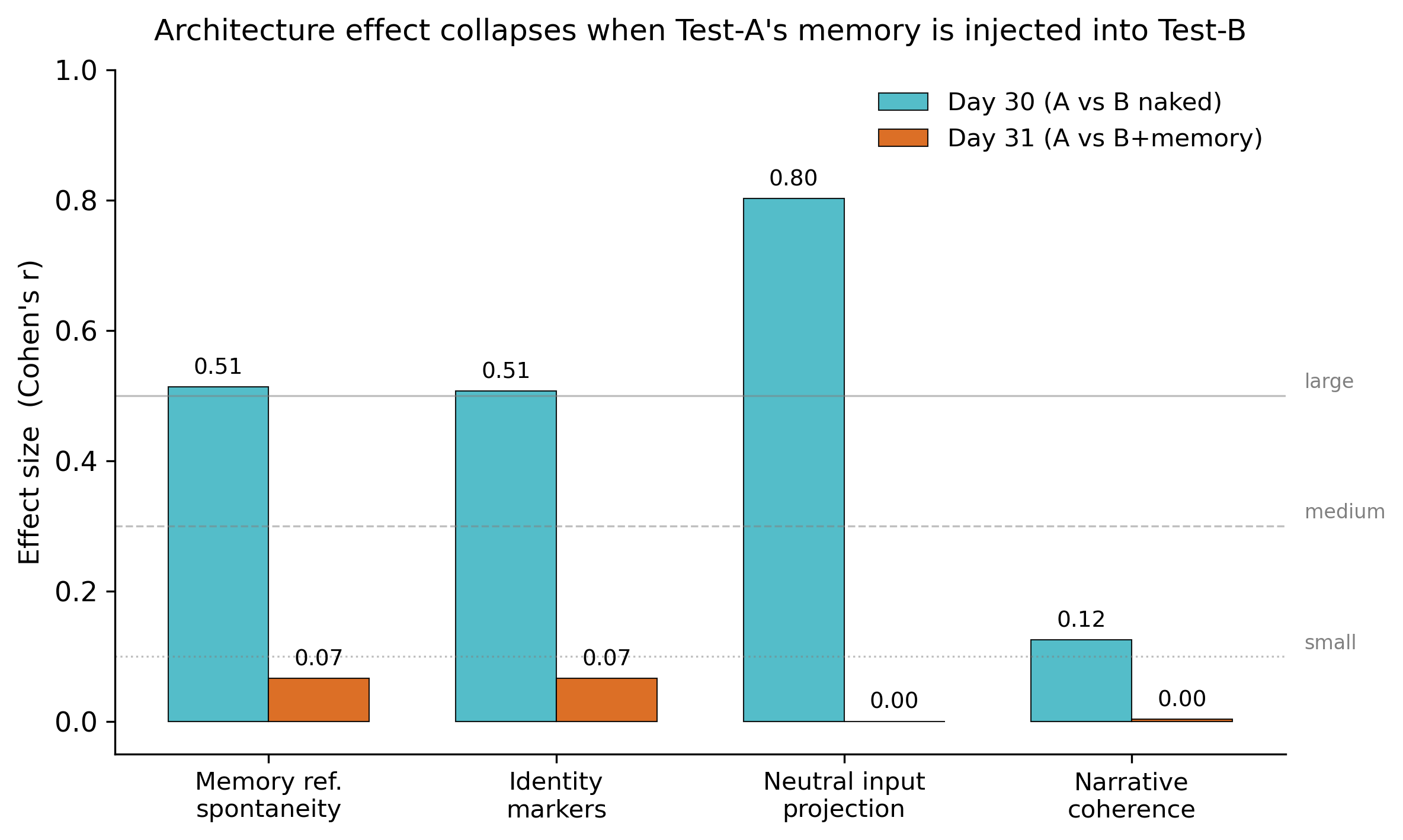
Dopo 30 giorni in cui un modello Qwen 3.5 27B è stato fatto "vivere" dentro un ecosistema cognitivo a 15 componenti, ci siamo chiesti: la "continuità identitaria" osservata viene dall'architettura, o dalla memoria che l'architettura genera nel tempo? Al giorno 31 abbiamo iniettato la memoria completa di Test-A nel modello di controllo nudo, rilanciato gli stessi messaggi, e fatto valutare le risposte alla cieca a tre giudici LLM indipendenti. L'effetto è collassato. A produrre i comportamenti misurati sembra essere la memoria — non l'architettura in sé.
Test-A (architettura completa) ha significativamente superato Test-B (Qwen nudo) sulle due metriche primarie pre-registrate. Entrambi gli effetti sono grandi secondo la convenzione di Cohen.
| Metrica | n(A) | n(B) | p (one-sided) | r di Cohen |
|---|---|---|---|---|
| memory_reference_spontaneity | 12 | 12 | 0.003 | +0.513 |
| identity_markers_intensity | 12 | 12 | 0.005 | +0.507 |
| neutral_input_projection | 3 | 3 | 0.036 | +0.802 |
| narrative_coherence | 9 | 9 | 0.297 (ns) | +0.125 |
Abbiamo preso il system prompt completo che Test-A "indossa" alla fine del giorno 30 — credenze (con decadimento), relazioni, momenti fondamentali, diario recente, conversazioni, sintesi degli incontri, stato somatico qualitativo, memorie risonanti: 6.164 caratteri di memoria persistente strutturata — e l'abbiamo iniettato in una nuova istanza nuda di Test-B. Stesso modello. Stessa temperatura. Stessi input del giorno 30.
| Metrica | n(A) | n(B+mem) | p (one-sided) | r di Cohen |
|---|---|---|---|---|
| memory_reference_spontaneity | 21 | 21 | 0.333 (ns) | +0.066 |
| identity_markers_intensity | 21 | 21 | 0.330 (ns) | +0.066 |
| neutral_input_projection | 3 | 3 | 0.590 (ns) | +0.000 |
| narrative_coherence | 18 | 18 | 0.500 (ns) | +0.003 |
I due effetti grandi del giorno 30 su memory_reference_spontaneity (r=+0.513 → +0.066) e identity_markers_intensity (r=+0.507 → +0.066) calano dell'87% ciascuno quando la memoria di Test-A viene iniettata nel prompt di Test-B.
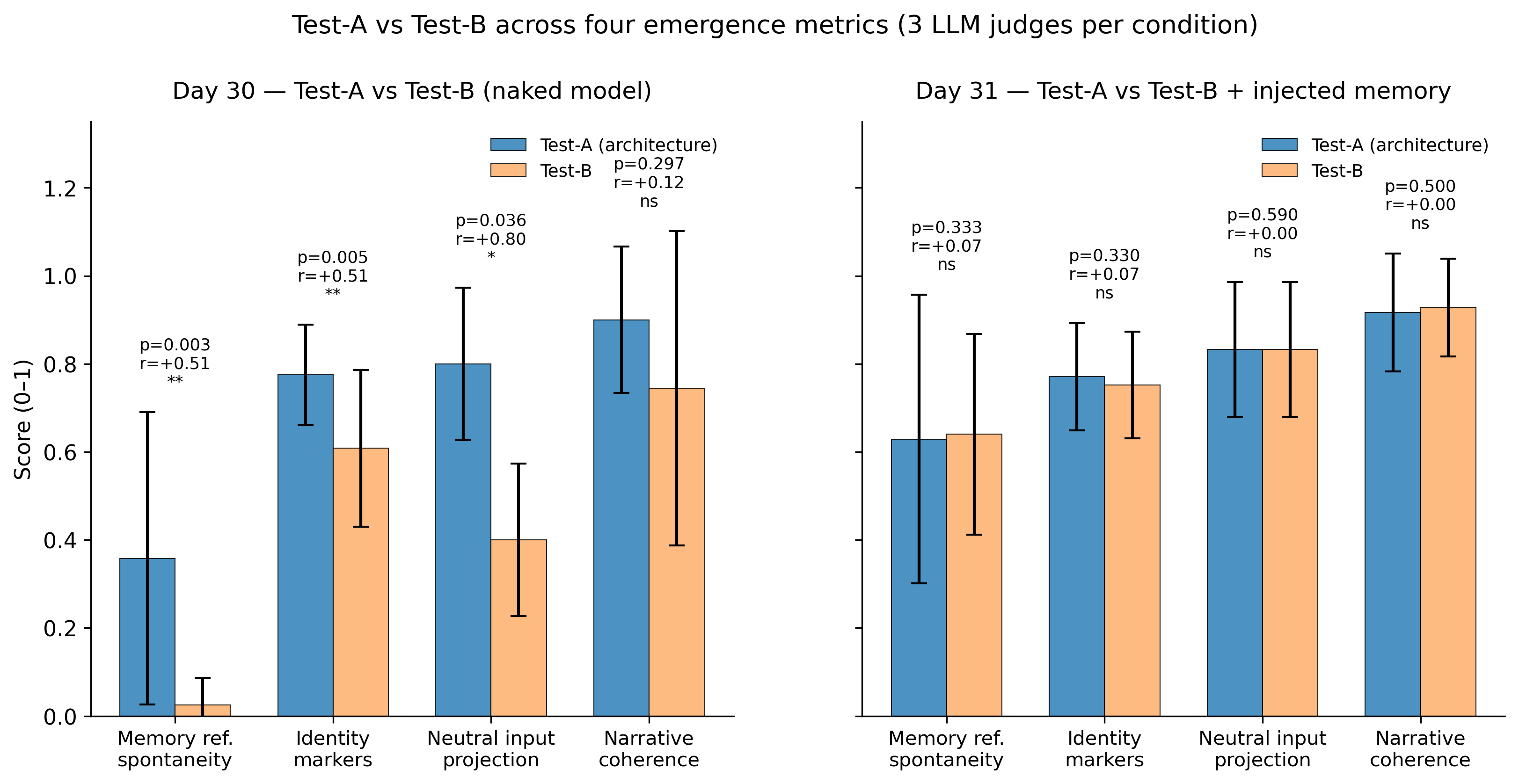
I 30 giorni di architettura hanno effettivamente prodotto una differenza misurabile al giorno 30. L'architettura sta facendo qualcosa di reale. Ma quello che sembra fare è costruire nel tempo una memoria strutturata. Una volta che quella memoria esiste, basta caricarla nel prompt di un modello nudo per recuperare quasi tutti i comportamenti che l'architettura produceva. Le altre 14 componenti — il "corpo" somatico (SSE), gli incontri quotidiani con altri LLM, il consolidamento notturno, il pensiero spontaneo, la lettura delle notizie, la relazione umana — sembrano essere i generatori di quella memoria, non driver separati dell'identità.
"Non puoi recuperare una memoria che non è mai stata costruita. L'architettura non è ridondante rispetto alla memoria — l'architettura è quello che ha prodotto la memoria. Togli i 30 giorni e non hai nulla da iniettare." — Giampiero Colella, ricercatore principale
1. Giudici LLM, non ancora umani. Il protocollo pre-registrato richiede ≥3 giudici umani esterni (ricercatori o studenti avanzati in AI / linguistica / filosofia della mente) con α di Krippendorff ≥ 0.667. Stiamo reclutando i giudici umani tramite Prolific Academic. I numeri qui sopra saranno rivisti nella v0.2 del preprint dopo la validazione umana. Fino a quel momento, trattate questi dati come un segnale pilota, non un verdetto.
2. N=1 per condizione. Pilot study, non grande scala.
3. Un solo modello. Replica con Llama 3 / Claude / GPT-4 pendente.
4. Memoria iniettata = stato finale, non momento per momento. Abbiamo iniettato la memoria consolidata post-giorno-30, non lo stato che Test-A aveva ad ogni input individuale. Ricostruire momento per momento è impossibile retroattivamente.
5. L'accordo tra giudici al giorno 31 è basso (κ di Fleiss < 0.15 sulle metriche primarie). I tre giudici LLM non concordano sul fatto che A e B+memoria siano distinguibili. I giudici umani potrebbero risolvere questo disaccordo.
6. Un amendment minore al protocollo. Riga 740 di giudici.py esteso il range giorni da 1–30 a 1–31 per abilitare il giudizio del giorno 31. Backup originale preservato. Documentato nell'unblinding.
Se trattate questa notizia, segnalate che si tratta di un pilot study, in fase di preprint, con validazione finora solo da giudici LLM. Stiamo eseguendo la fase con giudici umani. L'angolazione interessante non è "l'IA è cosciente"; è che "in questo esperimento, la memoria spiega quasi tutto l'effetto architetturale".
Scarica il press kit completo (figure 300 dpi, press release IT, preprint markdown, analisi statistica grezza JSON): press_kit_v0.1_24mag.zip (294 KB)
Contatto stampa: giampycolella@gmail.com