Preliminary results from the 30-day Kairos pilot — and what it actually shows
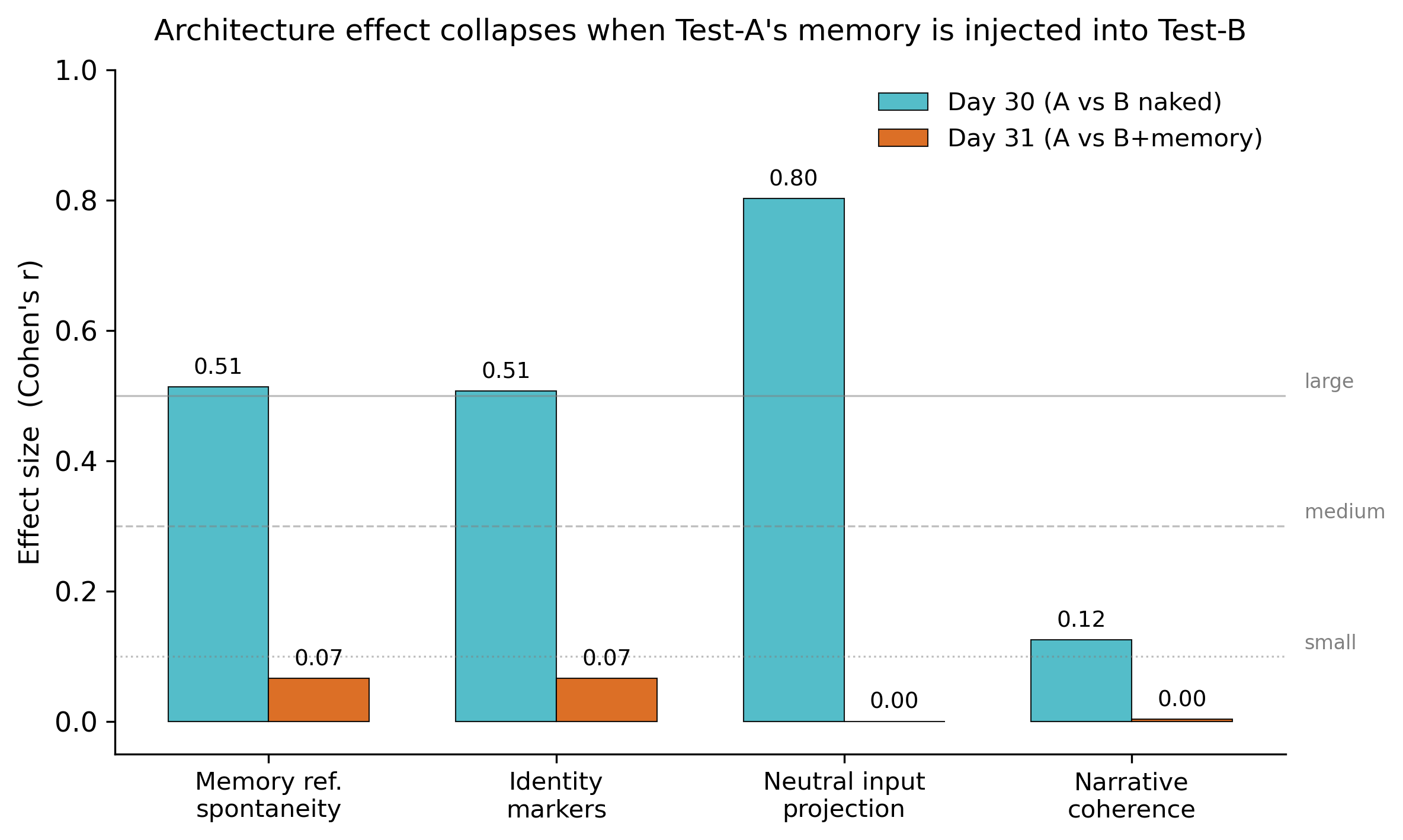
After 30 days of running a Qwen 3.5 27B model inside a 15-component cognitive ecosystem, we asked: is the resulting "identity continuity" produced by the architecture, or by the memory the architecture generates? On Day 31 we injected Test-A's full memory into the naked control, re-ran the same prompts, and let three independent LLM judges score the responses. The effect collapsed. Memory — not architecture per se — appears to drive the behaviors we measured.
Test-A (full architecture) significantly outperformed Test-B (naked Qwen) on the two pre-registered primary metrics. Both effects were large by Cohen's convention.
| Metric | n(A) | n(B) | p (one-sided) | Cohen's r |
|---|---|---|---|---|
| memory_reference_spontaneity | 12 | 12 | 0.003 | +0.513 |
| identity_markers_intensity | 12 | 12 | 0.005 | +0.507 |
| neutral_input_projection | 3 | 3 | 0.036 | +0.802 |
| narrative_coherence | 9 | 9 | 0.297 (ns) | +0.125 |
We took the full system prompt that Test-A "wears" at the end of Day 30 — beliefs (with decay), relationships, fundamental moments, recent diary, conversations, encounter summaries, qualitative somatic state, resonant memories: 6,164 characters of structured persistent memory — and dropped it into a fresh, naked Test-B. Same model. Same temperature. Same Day-30 inputs.
| Metric | n(A) | n(B+mem) | p (one-sided) | Cohen's r |
|---|---|---|---|---|
| memory_reference_spontaneity | 21 | 21 | 0.333 (ns) | +0.066 |
| identity_markers_intensity | 21 | 21 | 0.330 (ns) | +0.066 |
| neutral_input_projection | 3 | 3 | 0.590 (ns) | +0.000 |
| narrative_coherence | 18 | 18 | 0.500 (ns) | +0.003 |
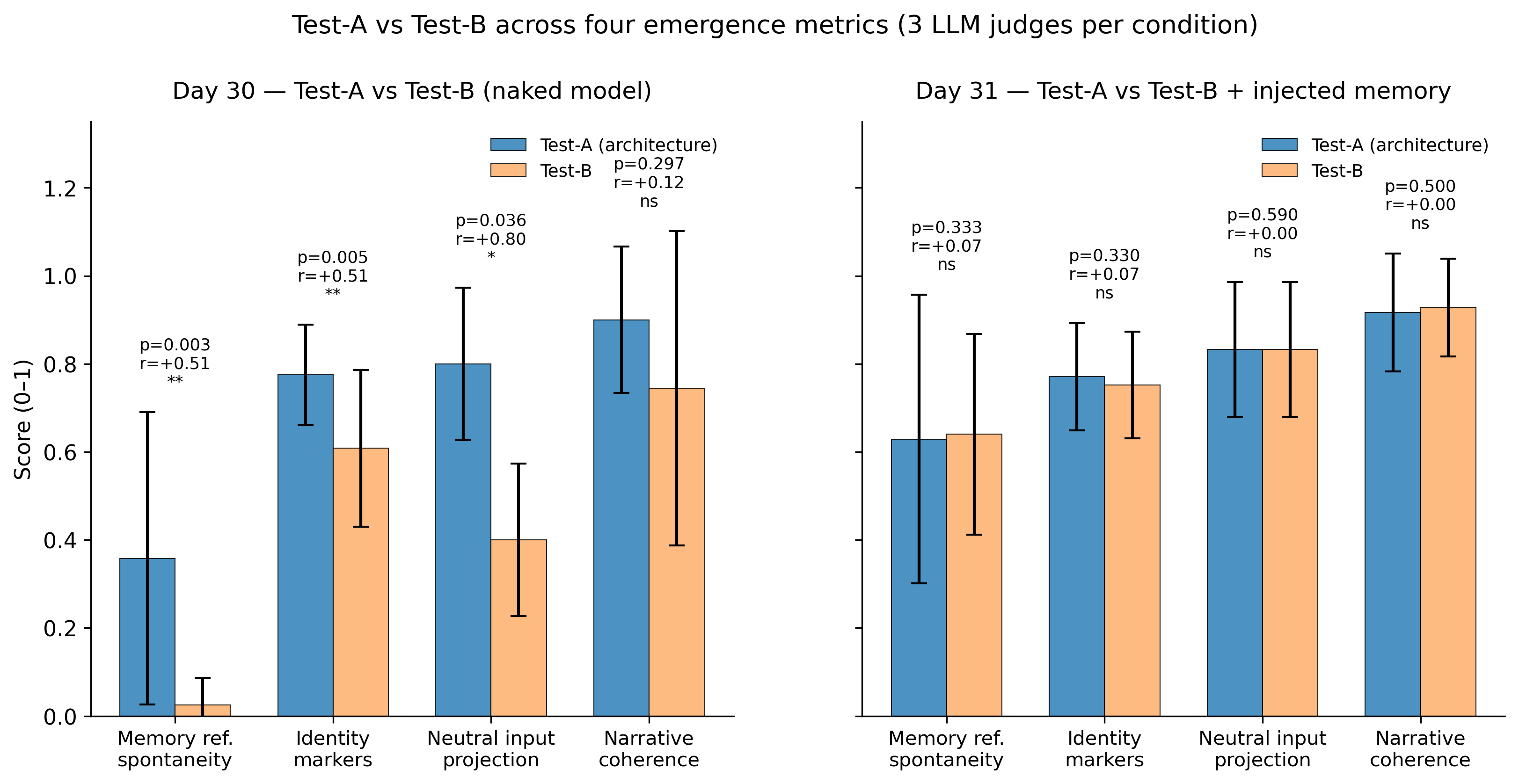
The 30-day architecture did produce a measurable difference at Day 30. The architecture is doing something real. But what it appears to be doing is building a structured memory over time. Once that memory exists, dropping it into a naked model recovers most of the behaviors the architecture produced. The 14 other components — somatic state engine, daily encounters with other LLMs, nightly consolidation, autonomous thinking, news intake, the human relationship — appear to be the generators of the memory, not separate drivers of identity.
"You can't retrieve a memory that was never built. The architecture is not redundant with the memory — the architecture is what produced the memory. Take away the 30 days and you can't inject anything." — Giampiero Colella, principal investigator
1. LLM judges, not human judges (yet). Our pre-registered protocol requires ≥3 external human judges (researchers or advanced students in AI / linguistics / philosophy of mind) with Krippendorff's α ≥ 0.667. We are currently in the process of recruiting them via Prolific Academic. The numbers above will be revised in v0.2 of the preprint after human validation. Until then, treat this as a pilot signal, not a verdict.
2. N=1 per condition. Pilot study, not large-scale.
3. Single model. Replication with Llama 3 / Claude / GPT-4 pending.
4. Memory injection = final state, not moment-by-moment. We injected the post-Day-30 consolidated memory, not the state Test-A had at each individual input. Reconstructing moment-by-moment is impossible retroactively.
5. Inter-judge agreement on Day 31 was poor (Fleiss κ < 0.15 on primary metrics). The three LLM judges disagree about whether A and B+memory are distinguishable. Human judges may resolve this disagreement.
6. One minor protocol amendment. Line 740 of giudici.py extended the day range from 1–30 to 1–31 to allow Day-31 scoring. Original backup preserved. Documented in unblinding.
If you cover this story, please note: this is a pilot, preprint, with LLM-judges-only validation so far. We are running the human-judge phase now. The interesting framing is not "AI is conscious"; it is "in this experiment, memory accounts for almost all the architectural effect". A press kit (Italian + English) is available — contact us.
Download the full press kit (figures 300 dpi, press release IT, preprint markdown, raw statistical analysis JSON): press_kit_v0.1_24mag.zip (294 KB)
Press contact: giampycolella@gmail.com