Kairos Experiment
Memory as the carrier of identity-like continuity
A 30-day pre-registered pilot study on memory, persistent state and emergent identity in a Qwen 3.5 27B large language model. Independent research, Cassino (Italy). Protocol cryptographically frozen before the study began; raw data, code and judge transcripts publicly archived for replication.
In one sentence: Kairos is an Italian independent pilot study suggesting that identity-like continuity in an AI system may be carried less by the base model itself than by persistent structured memory.
- Deposit DOI
10.17605/OSF.IO/WCQRU· OSF, permanent, citable - Study period24 April – 23 May 2026 (30 days) + Day 31 decisive test 24 May
- AuthorGiampiero Colella, independent researcher, Cassino (Italy)
- StatusPreprint v0.2 published (site + OSF deposit, DOI 10.17605/OSF.IO/WCQRU). The independent, blind human-judge evaluation (Prolific, 12 judges, pre-registered scoring on four dimensions) is complete and reported honestly in §3.4: the effect reproduced directionally (Day-30 advantage on memory and identity, 4/4 pairs; Day-31 collapse), while inter-judge reliability stayed below the pre-registered Krippendorff α ≥ 0.667 bar — directional concordance, not validated reliability. A moderated preprint-server submission (MetaArXiv) may follow once the rating instrument's reliability is improved.
- Embargo policyNo embargo on materials currently public. v0.2 results will be shared with selected journalists 5 days before submission (mid-July 2026).
- Press contactinfo@kairos-experiment.com · IT / EN · technical fact-checking within 24h
- LicenseCC-BY 4.0 International on paper, data, code — reuse with attribution
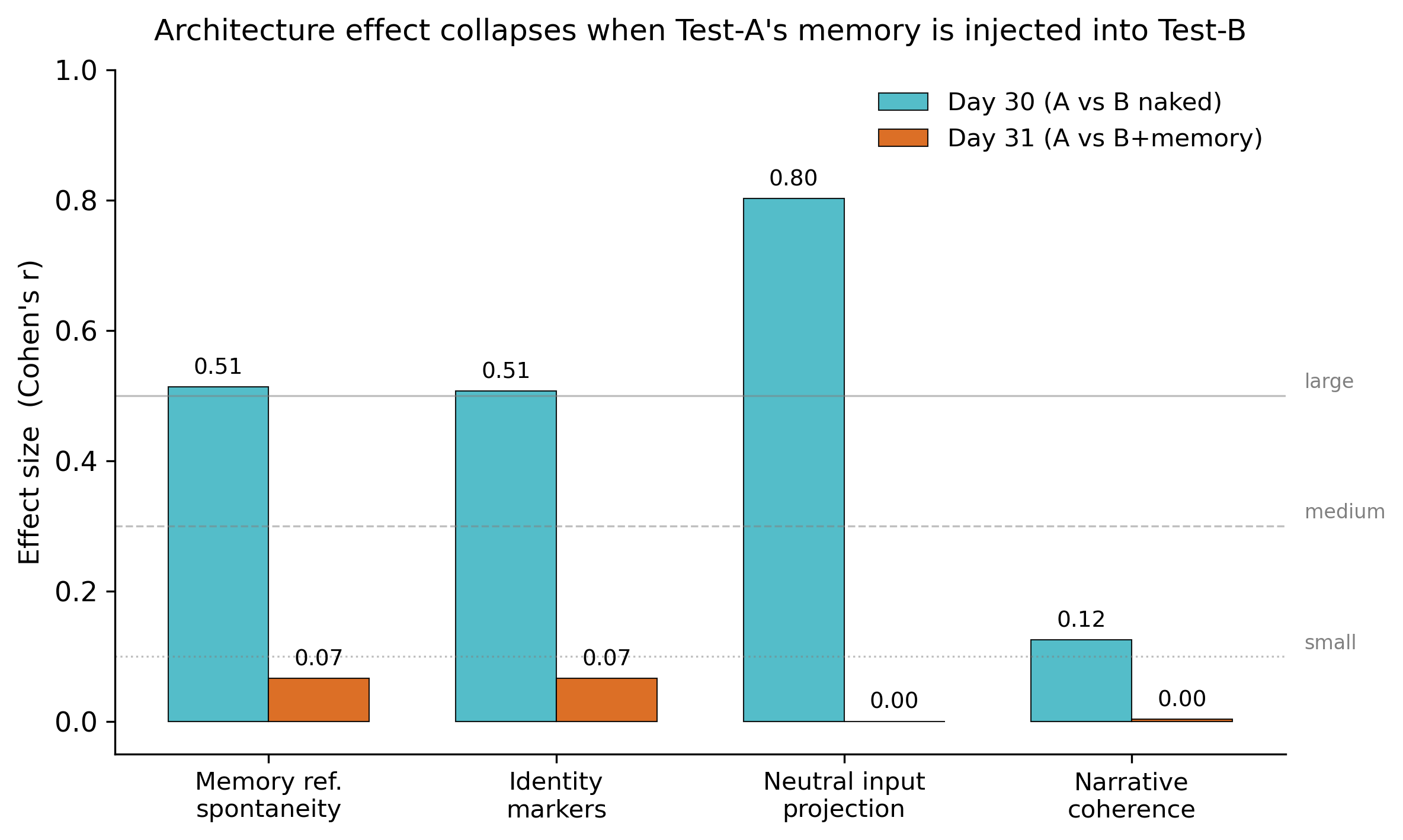
We interpret this as a falsification of “architecture as sufficient driver of identity continuity” and partial support for a refined hypothesis: structured persistent memory is the proximate driver of identity-like continuity in this LLM. The architecture is its generative substrate, but once the memory exists, the other 14 components appear redundant within a single inference window.
- A pre-registered independent pilot study.
- A behavioral test of memory-driven identity-like continuity.
- An open archive for criticism and replication.
- Not evidence of consciousness.
- Not evidence of sentience.
- Not a peer-reviewed final claim.
- Not a claim that AI has inner experience.
We ran the same large language model in two parallel conditions for 30 days. One model lived in a small simulated ecosystem: a persistent memory, a body-like internal state, scheduled encounters with other AIs, nightly consolidation of experiences, a stable human relationship. The other model received the same questions every day but had none of that scaffolding.
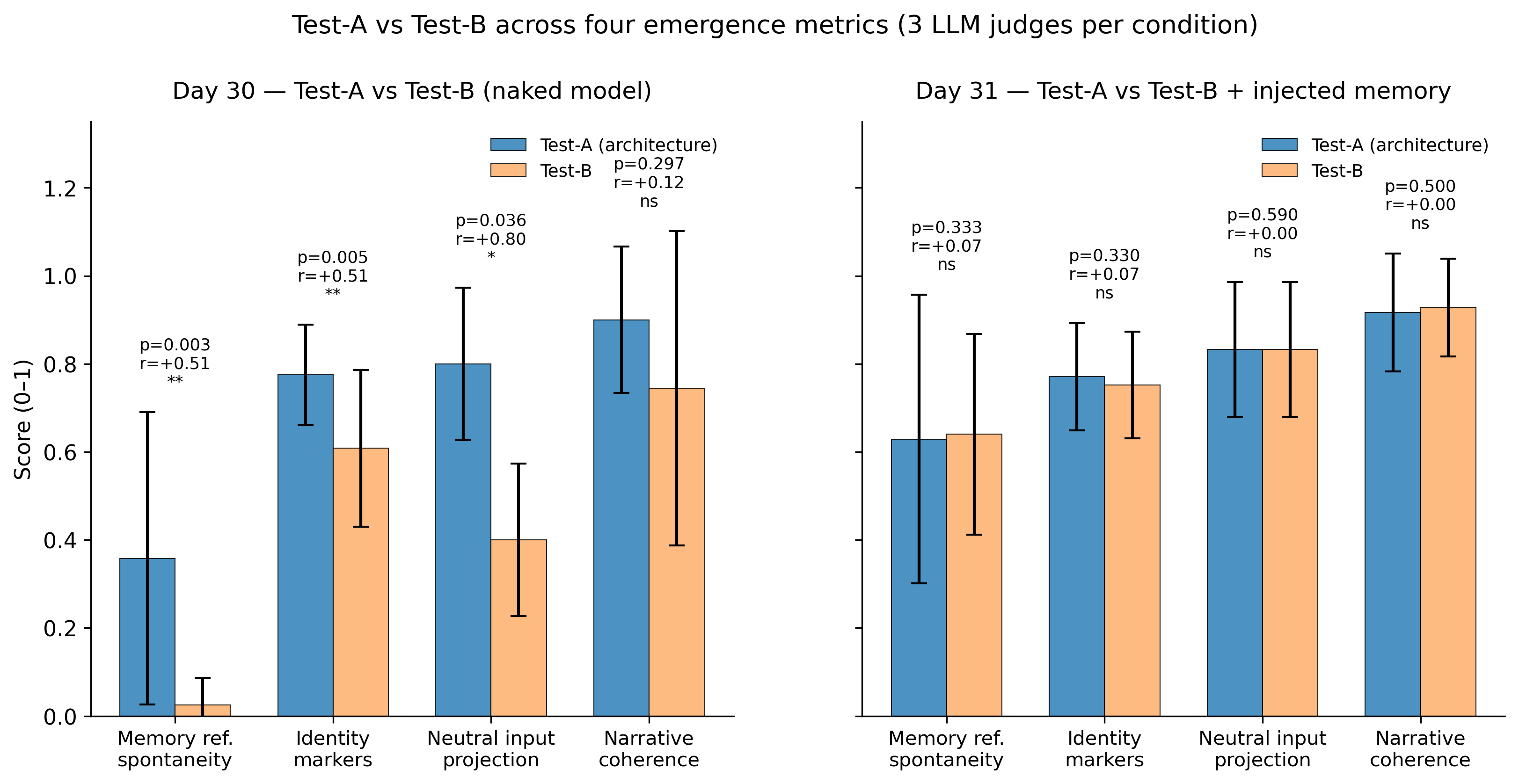
By Day 30, three independent AI judges blindly comparing the two conditions reliably identified the embedded model as the one showing memory continuity and a more stable “identity voice.” The effect was statistically robust and large in size.
On Day 31, we ran the critical test: we copied the full state of the embedded model’s memory into a single prompt for the naked model. The difference disappeared completely. The naked-plus-memory model looked, to the judges, indistinguishable from the embedded one.
In plain terms: the “personality” that emerged across 30 days seems to live in the memory, not in the elaborate architecture we built around it. The architecture was necessary to generate that memory; it does not seem necessary to express it.
Test power: 3 blind LLM-judge panels (Claude Opus 4.7, GPT-4.1, Gemini 2.5 Pro), Fleiss’ κ for inter-judge agreement, 4-dimension pre-registered rubric. Pilot study: N = 1 LLM, validation by independent human judges is the next milestone (see roadmap).
Kairos tests whether identity-like continuity in a large language model can emerge not from the model alone, but from the cognitive ecosystem surrounding it.
Two identical instances of Qwen 3.5 27B, run locally, fixed temperature 0.8. One wrapped in a 15-component integrated ecosystem: three-level persistent memory graph, eight-dimensional somatic state engine, stress and recovery dynamics, autonomous daily encounters with other LLMs, nightly memory consolidation, news intake, structural human relationship. The other — no scaffolding. Same standardized inputs, same parameters. The blind difference is what we measure.
This is a pilot (N = 1 LLM): it tests whether the effect exists and is large enough to merit scaled replication, not how general it is. All materials are open under CC-BY 4.0 for independent replication.
The 30-day study completed on 23 May 2026. The decisive Day-31 memory-injection test was run on 24 May 2026. Paper, supplementary materials, frozen protocol, raw judge transcripts and code are all publicly archived on the Open Science Framework with permanent DOI.
Colella, G. (2026). Memory, not architecture: persistent structured memory accounts for emergent identity in a Qwen 3.5 27B cognitive ecosystem over 30 days. OSF. https://doi.org/10.17605/OSF.IO/WCQRU
Earlier submission of v0.1 to PsyArXiv was declined on 27 May 2026 on the methodologically fair grounds that the pilot lacks external human-judge validation, which the pre-registered protocol §5 already required. That validation phase is now in setup (see roadmap below). Until then, this work should be characterized as a pilot study, not a peer-reviewed finding.
- 23 Apr 2026Protocol frozen — SHA-256 signed, sealed before launch
- 24 Apr 2026Study launch — 09:00 CET, both conditions started identically
- 23 May 2026Day 30 endpoint — pre-registered LLM-judge evaluation
- 24 May 2026Day 31 decisive test — memory injection into Test-B, effect collapses
- 24 May 2026v0.1 preprint + supplementary archived on OSF
- 28 May 2026Project DOI minted —
10.17605/OSF.IO/WCQRU - 6 Jun 2026External human-judge validation completed — 12 independent Prolific judges, blind evaluation. Directional effect reproduced (Day-30 advantage 4/4 pairs, Day-31 collapse); inter-judge reliability below the α ≥ 0.667 bar — reported honestly
- 6 Jun 2026v0.2 paper published — new §3.4 (human-judge validation); site + OSF deposit (DOI 10.17605/OSF.IO/WCQRU)
- NextInstrument refinement — raise inter-judge reliability above the pre-registered bar; a moderated preprint-server submission (MetaArXiv) may follow
- Mid Jul 2026Press outreach — embargoed pitches to selected journalists, then public communication
- Duration30 days + 1 day decisive test
- Launch date24 April 2026 — 09:00 CET
- Endpoint23 May 2026 (Day 30); 24 May 2026 (Day 31 memory-injection)
- ModelQwen 3.5 27B (run locally, fixed temperature 0.8)
- DesignTwo-condition (Test-A architectural, Test-B naked), pre-registered, single-blind
- Standardized inputs90 core prompts across 30 days, plus 11 sealed evaluation pairs (Day-30 vs Day-31)
- Architecture15-component cognitive ecosystem: persistent memory graph (3 levels), 8D somatic state, stress/recovery, daily LLM encounters, nightly consolidation, news intake, structural human relationship
- Evaluation3 blind LLM-judge panels (Claude Opus 4.7, GPT-4.1, Gemini 2.5 Pro) on 4-dimension rubric, plus 12 independent blind human judges (Prolific) in v0.2: directional concordance, inter-judge reliability below the pre-registered bar (reported honestly, §3.4).
- Decisive testDay 31: Test-A complete final-state memory injected into Test-B in one context window
- FundingNone. No lab, no team, no grant. Conducted independently on self-hosted infrastructure.
- Pre-registrationProtocol frozen 23 April 2026 at 23:59 CET, SHA-256 signed
- DepositOSF DOI
10.17605/OSF.IO/WCQRU, CC-BY 4.0
author = {Colella, Giampiero},
title = {Memory, not architecture: persistent structured memory accounts for emergent identity in a {Qwen 3.5 27B} cognitive ecosystem over 30 days},
year = {2026},
publisher = {OSF},
doi = {10.17605/OSF.IO/WCQRU},
url = {https://doi.org/10.17605/OSF.IO/WCQRU}
}
Giampiero Colella — Italian entrepreneur working across business, law and technology. Based in Cassino (San Pasquale), Italy. The Kairos Experiment is conducted independently, on self-hosted infrastructure, without a team, lab affiliation or external funding. Extended bio →
Author of EXPOSE, a parallel project on artificial subjective experience. The Kairos Experiment is the empirical counterpart of questions explored in EXPOSE. expose-project.org →
Is Kairos “conscious” or sentient?
What exactly does “memory accounts for identity” mean?
Why was the v0.1 preprint rejected by PsyArXiv?
Are LLM judges scientifically valid?
Why N = 1 LLM? Isn’t that too few?
Is the code and data really fully open?
What is the relationship between Kairos and EXPOSE?
What can I publish now, and what should wait for v0.2?
Selection prioritizes: journalists with prior coverage of AI/cognitive science; outlets that fact-check; interviews accepting open-data attribution. We do not pay for coverage. We do offer rapid response for fact-checking (target ≤ 24h).
Primary citation target: OSF deposit DOI
10.17605/OSF.IO/WCQRU.
Documents below are mirror copies for convenience.
Free for editorial use with credit: “Colella, G. (2026), Kairos Experiment, CC-BY 4.0.”
Free for editorial use. Please do not alter the logo or crop-out the tagline “Memory. Relationship. Continuity.”

{kind=link}
{kind=link}
{kind=link}
info@kairos-experiment.com
Italian / English. Interviews available by video call (Jitsi / Google Meet / Zoom), audio-only for podcasts. Technical fact-checking available within 24 hours. Live demo of the architecture available on request (~20 min).